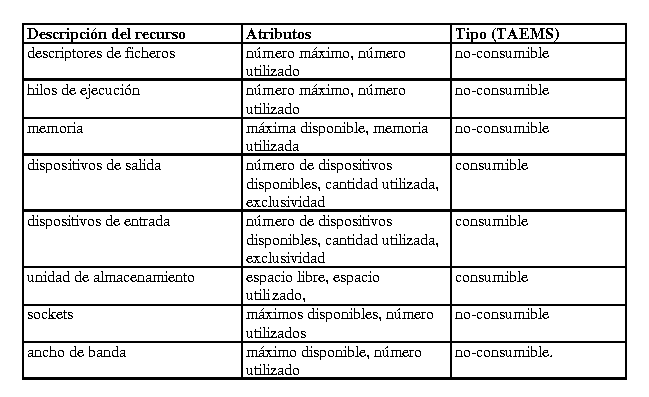
 Tabla
1. Enumeración de ejemplos de recursos
Tabla
1. Enumeración de ejemplos de recursosEn este meta-modelo el propósito no es generar representaciones del mundo en el que se ubica el SMA como hace, por ejemplo, [Ferber 99]. La experiencia en Inteligencia Artificial ha demostrado lo difícil de esta tarea. [Russell y Norvig 95] muestra que los entornos pueden ser accesibles (capacidad para percibir todo el entorno) o inaccesibles, deterministas (dado una codificación del estado del entorno y una acción ejecutada, se puede predecir el estado siguiente) o no-deterministas, episódicos (la experiencia del agente puede segmentarse en episodios independientes) o no episódicos, estático (el estado del mundo no cambia mientras el agente delibera) o dinámico, discreto (existe un conjunto finito de variables a observar y un conjunto finito de acciones posibles) o continuo. Lógicamente, el peor caso es un entorno inaccesible, no-episódico, dinámico y continuo, que suele ser la situación más común en problemas de control en tiempo real. El tipo de entorno influye en cómo se define la percepción del agente, sus acciones y su control.
Desde un punto de vista más pragmático, se ha decidido aplicar el enfoque de Situated Automata [Rosenschein y Kaelbling 95] y redes neuronales [Zilouchian 00]: discretizar el entorno utilizando un conjunto finito de variables observables. Desde este punto de vista, el problema se asemeja más a la situación con que se enfrentan los que diseñan sistemas empotrados. Esta discretización se aplica en dos direcciones: categorizar el tipo de entidades relevantes en el entorno y restringir la interacción con las mismas. Así, el entorno contendrá sólo recursos, aplicaciones y agentes, y se limitará la percepción y actuación de los agentes.
La aparición de recursos y su inclusión a los agentes se remonta a IRMA [Bratman, Israel y Pollack 88], donde la capacidad de razonamiento está limitada por los recursos disponibles, tiempo de procesador principalmente. Estos recursos van desde el número de procesos o hebras requeridos hasta el número de conexiones necesarias con bases de datos. Las aplicaciones pueden modelarse de distintas formas, en concreto, se estudiarán dos: abstracciones con objetos y con agentes. Por último, se considera la posibilidad de que existan otros agentes en el sistema. Para este caso, el comportamiento de estos agentes es modelable con los meta-modelos ya presentados.
Los mecanismos de percepción de los agentes son función directa de cómo se describen las entidades del sistema. La literatura muestra que hay dos mecanismos básicos: muestreo (polling) y notificación. En ese meta-modelo de entorno se definen las asociaciones de los agentes con estas entidades y el tipo de mecanismo utilizado para recibir datos del entorno. Las acciones sobre el entorno se asume que son llamadas a las operaciones que se definen en estas entidades.
La evolución del entorno se considera como la suma de la evolución de sus componentes (recursos, entidades y agentes) influenciada por las dependencias entre ellos (una acción sobre un recurso puede afectar a otras entidades). No se pretende llegar a modelar este tipo de sistemas, sin embargo, se quiere dejar la puerta abierta a desarrollos especializados en estas áreas. Para ello se añaden asociaciones para indicar la existencia de efectos colaterales (side-effects) y, para tener un problema tratable, se ha simplificado el problema de la representación. El estado del entorno se modela bajo la hipótesis de que el comportamiento del sistema resultante de tener en cuenta estas asociaciones no es distinguible del que no las considera.
Con esta simplificación, se pueden concebir las tareas como transformadoras del estado del mundo. La concurrencia de diferentes tareas que modifican el estado del entorno es algo a considerar en la definición del flujo de trabajo de la organización. Al final de estas consideraciones, se puede llegar a la conclusión errónea de que se pretende modelar completamente un entorno y las repercusiones de las acciones sobre él. Ciertamente, sería ideal el poder tener una formalización completa de entorno y efectos de las tareas. No obstante, es harto complejo conseguir algo así, sobre todo cuando se manejan más a menudo especificaciones informales que formales y cuando existe la posibilidad de que el entorno sea modificado por otras entidades ajenas al sistema en desarrollo.
Las aplicaciones además de servir como actuadores y sensores de los agentes, se utilizan para integrar software en el desarrollo del SMA. Para definir aplicaciones se ha elegido una solución de ingeniería del software, concretamente del Rational Unified Process (RUP) [Jacobson, Rumbaugh y Booch 99]. El entorno aparece como subsistemas con unas interfaces que deben utilizarse para interactuar con ellos (requisitos funcionales), como notas asociadas en los casos de uso (requisitos no funcionales) o bien dentro de los diagramas de despliegue (deployment) (requisitos físicos).
Ahora bien, como en RUP, existen varias opciones para modelar una aplicación:
Usando objetos. Las aplicaciones se recubren con una capa de objetos. La interactuación con estos componentes se define en términos de conceptos de UML (interfaces, diagramas de estados, diagramas de colaboración). Con esta solución, se integran subsistemas como sistemas propietarios o bases de datos, definiendo una interfaz y un comportamiento asociado al object.
Usando agentes. Genesereth [Genesereth 94] propone tres formas de convertir en agente: por transductor (transducer), mediante recubrimiento (wrapping) y reescritura. El primero consiste en modelar la entidad como un objeto y asociar este objeto con un agente, el cual se encarga de mediar con el resto de agentes. El segundo consiste en incrustar la entidad dentro de un agente, de tal forma que el agente redirija las peticiones a la propia entidad. El tercero consiste básicamente en reescribir la aplicación.
Dependiendo del dominio, una tendrá ventajas sobre las otras. La experiencia dicta que la solución menos costosa es la primera, ya que la segunda implica, además de generar objetos, el generar un agente o bien rescribir completamente la aplicación, lo cual es, en la mayoría de los casos, inaceptable.
Las aplicaciones pueden emplearse para modelar servicios pasivos, esto es, un conjunto de operaciones que no requiere la interacción con ningún agente y que son empleadas por varios agentes. Ejemplos de tales aplicaciones serían servicios de nombrado (Naming service), servicios de emparejamiento (matchmaking service) o gestión del ciclo de vida de agentes (Life cycle management). Estos servicios pueden existir previamente en el entorno o no. Para el segundo caso, se hablará de aplicaciones internas.
De forma más frecuente, servirían como interfaz con el mundo real. Así la generación de estas aplicaciones estaría relacionada con el estudio del entorno para obtener, siguiendo a [Barber, Botti y Onaindia 94], un conjunto de variables de entrada, que representan datos accesibles en un momento dado mediante muestreo o por disparo de interrupciones, y salida, que sirven generalmente como parámetros de las acciones a ejecutar como reacción del sistema ante los cambios del entorno. Estas variables, aquí aparecerían como métodos asociados a las aplicaciones, para lectura de datos o actuación sobre el entorno.
La integración de recursos en el desarrollo se toma de TAEMS [Decker 96;Decker y Lesser 95;Decker 95], donde los recursos se categorizan en:
Consumibles. Son recursos que con el uso se agotan pero que son restituibles.
No consumibles. El recurso se auto-restituye al término de la acción realizada sobre él.
Todos los recursos pueden pertenecer a un agente o ninguno (el que lo usa es el poseedor temporal). La capacidad de estos recursos se define con tres atributos del mismo tipo (real, entero, tipo compuesto). Los atributos son estado, nivel de uso mínimo y nivel de sobrecarga. El uso de un recurso hace que su estado decrezca hasta el nivel de uso mínimo, a partir del cual el recurso se inhabilita. Otra situación de inhabilitación es el restablecimiento excesivo del recurso, que incrementa su estado por encima del nivel de sobrecarga.
Las tareas se relacionan con los recursos mediante tres relaciones: consumición, producción y limitación. La relación de producción permite que una tarea restituya un recurso. La de limitación impone precondiciones para lanzar una tarea en función de la disponibilidad de recursos. Finalmente, la de consumición indica uso de un recurso, lo que conlleva una disminución del estado del recurso.
Esta forma de modelar los recursos, sin embargo, tiene un inconveniente: la aparición de interbloqueos, exclusión mutua e inanición. Se necesita incluir en la solución medios para gestionar los recursos de tal forma que todas las tareas tengan posibilidad de ejecutarse y que se elimine el riesgo de interbloqueo. La solución más sencilla consiste en centralizar la gestión de recursos e implementar una política FIFO (First In First Out) no expropiativa de gestión de tareas donde se ejecuten las tareas si existen todos los recursos necesarios para ello. Los recursos se piden de forma atómica, no por separado y se exije que no se pidan más recursos hasta la conclusión de la tarea, con lo que se rompen una de las cuatro condiciones de interbloqueo [Coffman, Elphick y Shoshani 71] (estrategia de prevención de interbloqueo [Tanenbaum y WoodHull 97]). Esta solución es poco elegante, pero satisface las necesidades actuales de este trabajo.
Tabla
1. Enumeración de ejemplos de recursos
Por último, queda por determinar qué recursos son esperables en un sistema. Con este objetivo se ha elaborado una lista de recursos extraida de dos fuentes: los recursos reconocidos en la parametrización del núcleo de sistema operativo de Linux v. 2.4.X y el gestor de seguridad de Java. La elección del primero se basa la experiencia de implantación en diferentes tipos de máquinas que respalda Linux y en su condición de código abierto. La elección del segundo se fundamenta en la portabilidad de código que caracteriza JAVA y en la prioridad asignada a cuestiones de seguridad, que ha llevado a identificar recursos que necesitan los programas JAVA en múltiples plataformas. La lista se ha reducido a la tabla Tabla 1.
Los atributos mencionados son compatibles con la notación de TAEMS, ya que todos ellos son expresables con umbrales y el estado actual. De hecho, en la tabla se ha añadido una columna para categorizar el recurso según la taxonomía de TAEMS.
La presentación del meta-modelo de entorno comienza restringiendo el tipo de elementos que van a aparecer. Se distinguen tres posibles tipos: agentes, recursos y aplicaciones. Por recurso se entiende toda aquel objeto del entorno que no proporciona una funcionalidad concreta, pero que es indispensable para la ejecución de tareas y cuyo uso se restringe a consumir o restituir. Cuando el uso sea más complejo, como la funcionalidad requirida de una base de datos, se empleará el término aplicación. Por último, la denominación de agente se emplea cuando la entidad satisfaga el principio de racionalidad.
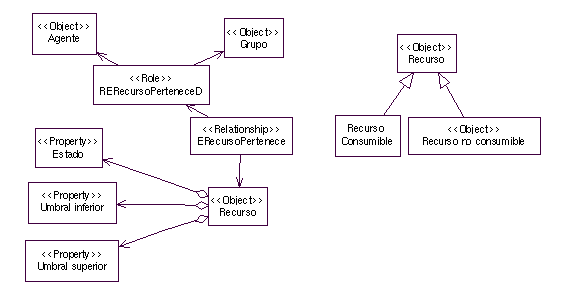
Ilustración 1. Meta-modelo de entorno. Recursos.
Los recursos pertenecen a un agente o a un grupo (RERecursoPertenece). Esta relación es similar a (OContieneGrupo) donde se indica únicamente si el grupo tiene un recurso. Dentro de esta relación se permite también que el recurso esté bajo el cuidado de un agente. Cada recurso se caracteriza con tres propiedades básicas: el estado actual, el umbral inferior y el umbral superior. Previendo categorizaciones distintas de la de TAEMS, se ha incorporado el tipo de recurso (consumible o no consumible) mediante herencia. Como ejemplo de posibles instancias de recursos, se pueden considerar los identificados en la Tabla 1. No se han incluido en el meta-modelo debido a que más que entidades del meta-modelo, se corresponden a instancias de Recurso Consumible o Recurso no consumible.
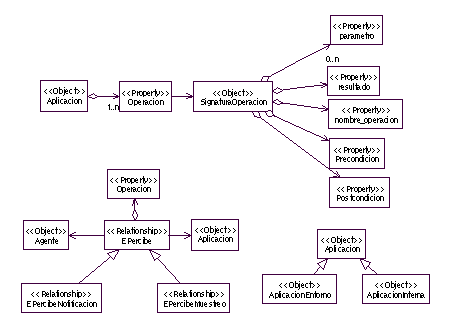
Ilustración 2. Meta-modelo de entorno. Aplicaciones y percepción
Las aplicaciones se caracterizan por poseer un conjunto de operaciones con una signatura convencional. Las precondiciones y postcondiciones se trasladan directamente de las especificaciones de la aplicación (las aplicaciones ya están desarrolladas así como la interfaz para interactuar con ellas) cuando esta sea un software existente. Estas operaciones se utilizan para modelar la percepción del agente. Inicialmente se distinguen sólo dos tipos: percepción: por muestreo y por notificación. En ambos tipos se asocia la percepción (EPercibe) con una operación concreta. En el caso de muestreo, operación es una operación que se va a ejecutar con una frecuencia determinada. Tiene sentido cuando aplicación representa un dispositivo hardware que hay que muestrear. En el caso de notificación, se percibe únicamente si se recibe un resultado distinto del que se recibió en la última invocación.
Las aplicaciones pueden existir con anterioridad al desarrollo actual (AplicacionEntorno) o ser desarrolladas ad-hoc para los propósitos actuales (AplicacionInterna). Las primeras se obtienen de la captura de requisitos, mientras que las segundas se generan mediante técnicas convencionales de ingeniería del software.
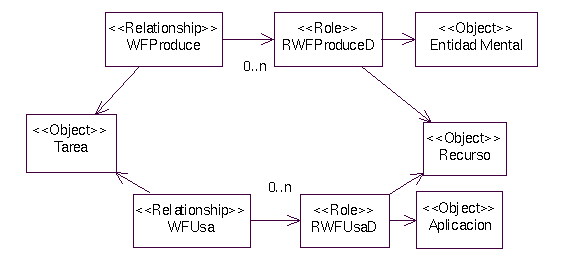
Ilustración 3. Meta-modelo de entorno. Tareas, recursos y aplicaciones
Tareas, recursos y aplicaciones se relacionan en la Ilustración 3. Como ya se ha visto en el meta-modelo de tareas y objetivos y en el meta-modelo de organización, la tarea consume y restituye recursos, pero también usa aplicaciones.
Se diseña un asistente del sistema operativo que gestiona la ubicación de ficheros en el disco duro. La gestión consiste en reorganizar los ficheros automáticamente según criterios extraídos por el agente extraídos del estudio de la relación fichero-directorio en función del tipo de fichero, palabras clave presentes en el contenido del fichero o en el nombre del fichero.
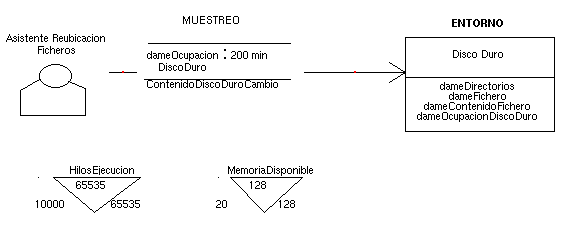
Ilustración 4. Descripción de aplicaciones y recursos para el caso de estudio
Para no afectar el funcionamiento normal del usuario, el agente atiende a la presencia de los recursos Hilos de Ejecución disponibles y Memoria Disponible. En la definición de los recursos se establecen el nivel mínimo de recursos que se debe observar (10000 hilos de ejecución y 20 Mb de memoria).
El agente respeta la organización de directorios existente ayudando a ubicar los nuevos ficheros en su lugar. El agente se activa cuando se produce un cambio en el espacio de disco ocupado (ver Ilustración 4). La consulta de espacio ocupado se realiza cada 200 minutos a través de la operación dameOcupacionDiscoDuro de una interfaz de acceso al disco duro (Disco Duro). Cuando se produce un cambio en el tamaño del disco duro, se genera un evento Contenido Disco Duro Cambio según lo establecido en la relación de percepción por muestreo de la Ilustración 4. Este hecho posibilita la ejecución de la tarea Analizar Ficheros tal y como indica la Ilustración 5.
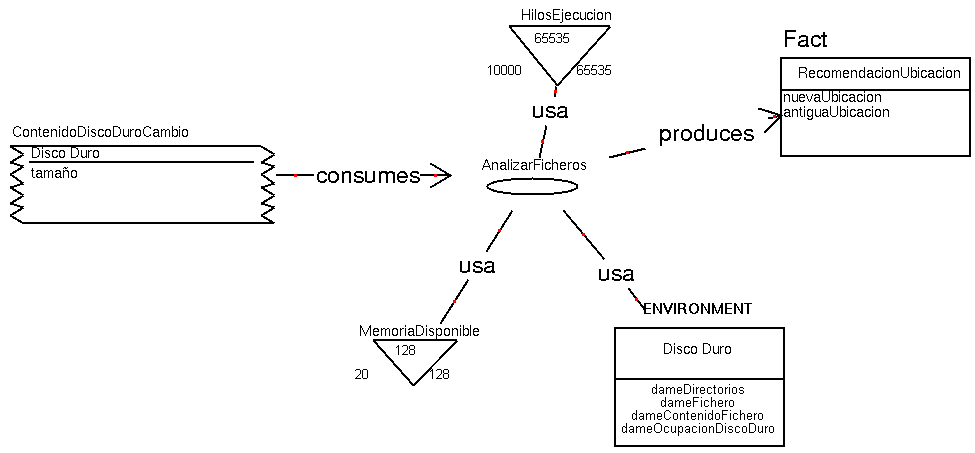
Ilustración 5. Tarea asociada al asistente para deducir la nueva ubicación de los ficheros
La tarea Analizar Ficheros consume los recursos Hilos Procesador y Memoria Disponible y el evento Contenido Disco Duro Cambio. Si no hubiera suficientes recursos, la tarea simplemente no se ejecutaría. Analizar Ficheros utiliza la aplicación Disco Duro (interfaz para acceder al disco duro) para obtener información acerca de qué existe en el dispositivo de almacenamiento. Como resultado de la tarea, se obtiene un hecho Recomendación Ubicación donde se indica qué movimientos de ficheros son necesarios.
El asistente puede coexistir con otros para lograr la automatización de tareas del Sistema Operativo. Los asistentes se dispondrían mediante un modelo de organización como el de la Ilustración 6.
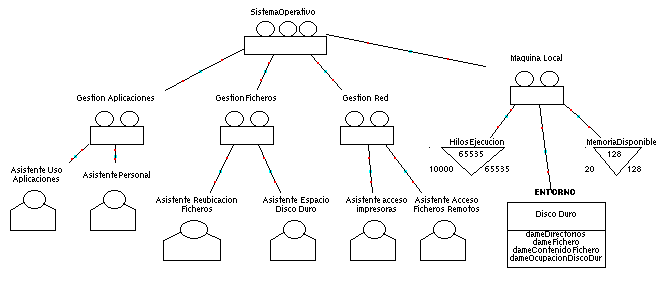
Ilustración 6. Organización de agentes asistentes en la máquina del usuario
Los recursos de la máquina del usuario se meten en el grupo Maquina Local. Estos recursos son utilizados por los agentes pertenecientes al resto de grupos (Gestión Aplicaciones, Gestión Ficheros, Gestión Red)
La principal función del meta-modelo de entorno es identificar los elementos del entorno y relacionarlos con el resto de entidades del sistema. El meta-modelo de entorno se relaciona con tres meta-modelos (Ilustración 7). El entorno, tal y como ha sido planteado, no aporta nada a las interacciones, aunque se vea afectado por las tareas que son ejecutadas dentro de las mismas. No obstante estas consecuencias ya se reflejan en otros modelos.
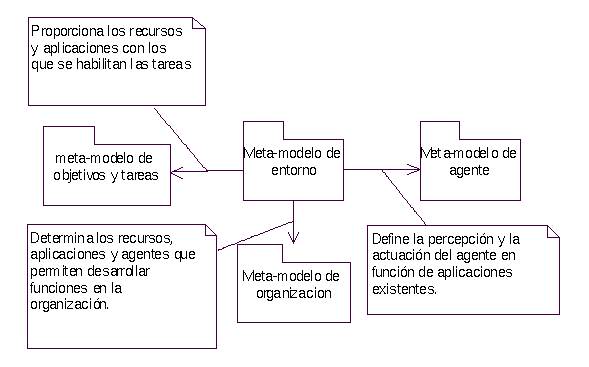
Ilustración 7. Meta-modelo de entorno. Relaciones con otros meta-modelos
Al meta-modelo de agente aporta la definición de la percepción de cada agente. Esta percepción, como se ha visto, se expresa mediante relaciones con aplicaciones. Al meta-modelo de organización le da el conjunto de recursos, aplicaciones y agentes disponibles. Por último, el meta-modelo de objetivos y tareas obtiene del entorno el conjunto de recursos que habilitan la tarea y las aplicaciones utilizadas para expresar las acciones realizadas.
Basándose en estas relaciones, se proponen los siguientes criterios de validación:
Todo recurso o aplicación que aparezca en los modelos de organización o tareas y objetivos, debe aparecer también en algún modelo de entorno.
Todo agente que aparezca en algún modelo de la organización o de agente y que según los requisitos del sistema deba percibir cambios en el entorno, debe aparecer en el de entorno asociado con una aplicación.
Las instancias de aplicación deben recoger el conjunto de operaciones descubiertas al detallar el funcionamiento de las tareas dentro de los modelos de tareas y objetivos.
Los recursos y aplicaciones deben asignarse a un grupo o agente. Esta información se indicar en un modelo de organización.